4.1 Data Wrangling and Advanced Indexing¶
Goal: Build data wrangling skills to clean and navigate datasets.
Outline:
Numpy Array and DataFrame methods and functions
Table indexing and slicing
Boolean (logical) indexing
Sorting
Data cleaning and inspection
Additional Required Reading: Functions¶
Data 8 textbook “Computational and Inferential Thinking: The Foundations of Data Science” By Ani Adhikari and John DeNero Chapter 8 Functions and Tables. This should overlap with your assigned reading for Data 8.
Numpy Arrays and DataFrames¶
NumPy and Pandas offer several types of data structures, the two main structures that we use are nparray and DataFrame. A nparray is a fast and flexible container for large datasets that allows you to perform operations on whole blocks of data at once. nparrays are best suited for homogenous (just one type) numerical data. DataFrames are designed for tabular datasets, and can handle heterogenous data (multiple types: int, float, string, etc.).
import numpy as np
import pandas as pd
nparray¶
Here is an example of a nparray with random float data:
# Generate a random nparray called arr_data
arr_data = np.random.randn(5,3)
arr_data
array([[-0.57998804, 0.97899567, -0.34593897],
[ 0.72785995, -0.04733108, -0.78786345],
[-1.28304881, -0.39334651, -0.70548535],
[ 0.07545761, -1.38557708, -0.58136571],
[-0.78433025, 1.77762604, 0.18444014]])
The function arrayName.shape is useful for finding the number of rows and columns in an array.
# use .shape to determine the shape of arr_data
arr_data.shape
(5, 3)
arrayName.dtype will display the data type of the data stored in the array.
# use .dtype to determine the type of arr_data
arr_data.dtype
dtype('float64')
The functions np.zeros and np.ones are similar, they create arrays full of zeros and ones respectively. The input for these functions is the shape of the array you want. This is an effective way of setting up an array of place-holders that you can then fill in with a loop or to make an array of a single value.
# Generate a nparray of zeros with np.zeros
arr0 = np.zeros((4,4))
arr0
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
# Generate a nparray of ones with np.ones
arr1 = np.ones((4,4))
arr1
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
# np.ones is handy for making a nparray of any single value
arr5 = arr1 * 5
arr5
array([[5., 5., 5., 5.],
[5., 5., 5., 5.],
[5., 5., 5., 5.],
[5., 5., 5., 5.]])
The functions np.arange and np.linspace can be used to make monotonic number lines. They are really useful! np.arange makes an array of integers or floats between the starting and ending (note that the ending point is exclusive) in steps that you set as inputs. np.linspace will make evenly spaced float points between the starting and ending (note that the ending point is inclusive) you set.
# Generate an array of integers between 0 and 10 in steps of 1, including 0 (start) but not 11 (end)
arr2 = np.arange(0,11,1)
arr2
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# Generate an array of floats between 0 and 10 in steps of 2, including 0 (start) but not 11 (end)
arr2 = np.arange(0.0,11.0,2.0)
arr2
array([ 0., 2., 4., 6., 8., 10.])
# Generate an array of 14 evenly spaced numbers between 0 and 10, including 0 (start) and 10 (end).
arr3=np.linspace(0,10,14)
arr3
array([ 0. , 0.76923077, 1.53846154, 2.30769231, 3.07692308,
3.84615385, 4.61538462, 5.38461538, 6.15384615, 6.92307692,
7.69230769, 8.46153846, 9.23076923, 10. ])
DataFrames¶
Series and DataFrames are like nparrays but they have the added feature of index labels assigned to each row and column – the bold labels in the below DataFrame. These labels can be used to bin and select data.
# generate a new DataFrame
# note that index values (like the column labels) don't have to integers and don't have to be in order
frame = pd.DataFrame(np.random.rand(3, 3), index=['Nevada','Montana','Arizona'], columns=['sedimentary','igneous','metamorphic'])
frame
| sedimentary | igneous | metamorphic | |
|---|---|---|---|
| Nevada | 0.080129 | 0.383692 | 0.369028 |
| Montana | 0.386677 | 0.934536 | 0.226119 |
| Arizona | 0.377186 | 0.122905 | 0.989476 |
We’ve seen DataFrame structures before in our tabular data files. The Earthquake catalog we were dealing with last week was a .csv (Comma Separated Variable) data file of all the earthquakes. We imported it as a DataFrame from the USGS API by setting up a query URL and using pd.read_csv. This time we’ll look at the earthquakes of magnitude 2.5 and greater from the past week.
start_day = '2020-09-07'
end_day = '2020-09-14'
standard_url = 'https://earthquake.usgs.gov/fdsnws/event/1/query?format=csv&orderby=magnitude'
query_url = standard_url + '&starttime=' + start_day + '&endtime=' + end_day + '&minmagnitude=2.5'
EQ_data = pd.read_csv(query_url)
EQ_data .head()
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | ... | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-09-07T06:12:39.688Z | -17.1102 | 168.5034 | 10.0 | 6.2 | mww | NaN | 41.0 | 2.072 | 1.03 | ... | 2020-11-29T09:47:05.444Z | 72 km NNE of Port-Vila, Vanuatu | earthquake | 6.9 | 1.8 | 0.058 | 29.0 | reviewed | us | us |
| 1 | 2020-09-11T07:35:57.187Z | -21.3968 | -69.9096 | 51.0 | 6.2 | mww | NaN | 72.0 | 0.077 | 0.88 | ... | 2020-11-21T20:10:36.040Z | 82 km NNE of Tocopilla, Chile | earthquake | 6.3 | 1.9 | 0.071 | 19.0 | reviewed | us | us |
| 2 | 2020-09-12T02:44:11.224Z | 38.7482 | 142.2446 | 34.0 | 6.1 | mww | NaN | 47.0 | 2.232 | 0.97 | ... | 2020-11-21T20:10:37.040Z | 58 km SE of Ōfunato, Japan | earthquake | 5.7 | 1.7 | 0.057 | 30.0 | reviewed | us | us |
| 3 | 2020-09-08T00:45:20.853Z | -4.8713 | 129.7548 | 172.0 | 5.9 | mww | NaN | 13.0 | 3.154 | 0.78 | ... | 2020-11-17T19:44:53.040Z | 193 km SSE of Amahai, Indonesia | earthquake | 5.3 | 1.8 | 0.098 | 10.0 | reviewed | us | us |
| 4 | 2020-09-12T08:34:27.321Z | -17.2562 | 167.6792 | 10.0 | 5.9 | mww | NaN | 64.0 | 1.856 | 0.69 | ... | 2020-11-21T20:10:38.040Z | 85 km NW of Port-Vila, Vanuatu | earthquake | 6.8 | 1.9 | 0.043 | 51.0 | reviewed | us | us |
5 rows × 22 columns
We have seen referencing individual columns (which are called Series) with: DataFrame['Column_Name'].
EQ_data['depth']
0 10.00
1 51.00
2 34.00
3 172.00
4 10.00
...
446 36.40
447 1.87
448 25.60
449 6.90
450 24.04
Name: depth, Length: 451, dtype: float64
The .values function can be used to return the values of the Series as a nparray, so without the labled index values of the Series.
print(type(EQ_data['depth']))
<class 'pandas.core.series.Series'>
EQ_data['depth'].values
array([1.0000e+01, 5.1000e+01, 3.4000e+01, 1.7200e+02, 1.0000e+01,
1.0000e+01, 1.7000e+01, 1.0000e+01, 5.5966e+02, 2.5000e+01,
1.0000e+01, 3.0920e+01, 3.1061e+02, 1.3893e+02, 5.8030e+01,
1.3380e+02, 1.0000e+01, 1.0000e+01, 5.7700e+01, 1.0000e+01,
1.3161e+02, 1.0000e+01, 1.0000e+01, 3.8760e+01, 3.5000e+01,
1.0000e+01, 1.2154e+02, 1.4900e+01, 1.0000e+01, 1.0125e+02,
7.3140e+01, 1.0000e+01, 3.5000e+01, 1.0000e+01, 1.0000e+01,
1.0000e+01, 1.0000e+01, 1.0000e+01, 6.0190e+01, 1.0956e+02,
1.3670e+01, 4.1180e+01, 2.5640e+01, 1.0000e+01, 9.1090e+01,
1.0000e+01, 1.0000e+01, 4.1160e+01, 4.6839e+02, 1.0000e+01,
1.0000e+01, 1.1292e+02, 1.0000e+01, 1.0000e+01, 9.9500e+00,
1.0000e+01, 1.0000e+01, 6.9820e+01, 1.0000e+01, 1.0000e+01,
1.0000e+01, 1.5297e+02, 1.0000e+01, 1.0000e+01, 1.0000e+01,
1.0000e+01, 1.0470e+01, 5.3357e+02, 1.0000e+01, 1.0000e+01,
1.0000e+01, 1.0000e+01, 6.3290e+01, 1.0000e+01, 1.0000e+01,
1.0000e+01, 1.2395e+02, 7.6540e+01, 3.5000e+01, 1.4690e+01,
1.4010e+01, 1.0000e+01, 1.0000e+01, 3.5000e+01, 1.0000e+01,
1.0000e+01, 1.0000e+01, 1.0000e+01, 1.0000e+01, 2.1316e+02,
7.4360e+01, 6.7880e+01, 1.0000e+01, 1.6725e+02, 5.3140e+01,
3.5000e+01, 1.0000e+01, 2.5090e+01, 1.0000e+01, 1.8132e+02,
3.5000e+01, 1.3016e+02, 1.0000e+01, 4.8605e+02, 4.2380e+01,
1.0391e+02, 2.3725e+02, 4.5090e+01, 5.1830e+01, 1.0000e+01,
1.0000e+01, 3.5000e+01, 4.3770e+01, 3.5000e+01, 2.0400e+01,
1.4044e+02, 1.0000e+01, 1.0000e+01, 1.0000e+01, 1.0000e+01,
1.0000e+01, 4.5140e+01, 1.6290e+01, 3.5000e+01, 2.9330e+01,
1.0000e+01, 1.0000e+01, 1.0000e+01, 1.0000e+01, 1.0000e+01,
2.5010e+01, 1.8181e+02, 1.0000e+01, 3.5000e+01, 1.0000e+01,
1.6640e+01, 1.0000e+01, 8.6100e+01, 1.8800e+02, 9.0490e+01,
1.0000e+01, 1.0000e+01, 1.9186e+02, 1.0000e+01, 1.0000e+01,
3.5000e+01, 1.0000e+01, 1.1536e+02, 1.0000e+01, 1.0000e+01,
3.7721e+02, 6.3670e+01, 7.8550e+01, 5.1430e+01, 2.4226e+02,
4.5660e+01, 1.0000e+01, 1.5310e+02, 1.3880e+01, 8.8000e+00,
1.0000e+01, 6.5570e+01, 4.0000e+01, 3.5000e+01, 5.3160e+01,
9.4700e+00, 2.7230e+01, 1.0000e+01, 6.0520e+02, 1.5339e+02,
1.0000e+01, 1.0000e+01, 4.0940e+01, 1.0000e+01, 1.0000e+01,
1.0000e+01, 6.7050e+01, 1.2725e+02, 1.3770e+01, 1.2202e+02,
1.0000e+01, 1.0028e+02, 1.0000e+01, 1.0000e+01, 1.2170e+02,
1.0000e+01, 4.9036e+02, 7.1140e+01, 4.0090e+01, 3.7430e+01,
1.0000e+01, 5.5077e+02, 6.4040e+01, 9.3300e+00, 5.2798e+02,
3.9300e+00, 1.0000e+01, 4.0810e+01, 2.7372e+02, 1.0000e+01,
1.0000e+01, 5.1980e+01, 1.0000e+01, 1.0000e+01, 3.5000e+01,
1.0000e+01, 1.0000e+01, 2.1000e+00, 1.2016e+02, 5.3610e+01,
6.8400e+01, 7.3150e+01, 2.1260e+02, 1.6893e+02, 7.8770e+01,
1.7110e+02, 4.8255e+02, 3.5000e+01, 1.0000e+01, 3.1160e+01,
4.7420e+01, 3.6170e+01, 6.2320e+01, 1.0073e+02, 1.1993e+02,
2.9170e+01, 1.0000e+01, 1.1844e+02, 1.7430e+01, 1.0000e+01,
6.1590e+01, 1.8810e+01, 1.5361e+02, 9.2860e+01, 4.8296e+02,
7.6560e+01, 1.0000e+01, 1.0000e+01, 1.0000e+01, 5.3973e+02,
5.0372e+02, 5.9451e+02, 5.3977e+02, 8.8560e+01, 1.0000e+01,
4.4250e+01, 3.0500e+01, 3.5000e+01, 1.0000e+01, 1.8704e+02,
1.0000e+01, 3.1700e+01, 2.1725e+02, 1.9963e+02, 2.3488e+02,
1.4845e+02, 4.6990e+01, 1.0000e+01, 8.0770e+01, 1.0000e+01,
3.8000e+01, 3.7000e+01, 5.0000e+00, 6.0000e+01, 3.3000e+01,
3.8000e+01, 3.7000e+01, 7.0890e+01, 1.0000e+01, 1.0400e+01,
3.7000e+00, 3.2600e+01, 2.0000e+01, 1.2900e+02, 4.5000e+01,
1.0100e+01, 3.5000e+01, 2.6500e+01, 1.8000e+00, 1.6790e+01,
1.0000e+01, 3.4700e+01, 4.0000e+00, 5.0000e+00, 6.0000e+00,
1.3000e+01, 1.1000e+01, 1.1000e+01, 2.3400e+00, 2.5110e+01,
3.6400e+01, 1.0000e+01, 1.2000e+01, 5.3000e+01, 1.3000e+01,
8.3100e+01, 1.3110e+01, 3.5000e+01, 0.0000e+00, 1.1780e+01,
1.5880e+01, 1.3000e+01, 6.0000e+00, 1.1000e+01, 1.4000e+01,
1.5530e+01, 5.6100e+00, 5.0000e+00, 8.4880e+01, 2.4840e+01,
3.2940e+01, 1.1000e+01, 6.0000e+00, 1.1000e+01, 1.3000e+01,
5.0000e+00, 3.5000e+01, 1.0000e+01, 1.4648e+02, 1.0000e+01,
1.0000e+01, 1.0000e+01, 1.4638e+02, 1.0000e+01, 1.4429e+02,
1.0000e+01, 9.0000e+00, 1.2000e+01, 6.8300e+00, 1.3000e+01,
8.0000e+00, 1.0000e+01, 1.3790e+01, 1.1000e+01, 1.2000e+01,
2.3490e+01, 8.0000e+00, 2.0370e+01, 9.0000e+00, 1.0000e+01,
1.0000e+01, 1.0000e+01, 1.3727e+02, 1.4000e+01, 3.6500e+01,
1.4700e+01, 7.6770e+01, 0.0000e+00, 2.5080e+01, 9.8420e+01,
1.0000e+01, 1.0000e+01, 1.0000e+01, 1.1000e+01, 5.5900e+00,
1.1000e+01, 1.4000e+01, 1.8800e+00, 3.1000e+00, 6.9600e+01,
1.4100e+01, 1.0000e+01, 1.0000e+01, 1.7800e+01, 3.5200e+01,
5.4000e-01, 4.5300e+01, 1.3600e+00, 1.0000e+01, 1.5000e+01,
1.8000e+01, 6.3500e+00, 6.9700e+00, 1.0000e+01, 9.0000e+00,
1.8000e+01, 6.7800e+00, 1.5597e+02, 5.0000e+00, 9.1100e+01,
4.7000e+00, 2.4100e+00, 3.7000e+00, 1.0000e+01, 3.5000e+01,
1.2240e+01, 1.2050e+02, 2.5680e+01, 2.5570e+01, 3.2240e+01,
3.7300e+00, 1.8900e+00, 4.4100e+00, 1.4000e+01, 1.1000e+01,
9.0000e+00, 1.3000e+01, 1.0000e+01, 2.1000e+01, 1.0000e+01,
6.9800e+00, 1.0000e+01, 1.1900e+00, 9.0000e+00, 1.2000e+01,
1.4000e+01, 7.5000e+00, 2.6670e+01, 5.3600e+01, 4.5690e+01,
5.6910e+01, 3.0810e+01, 1.6000e+01, 1.2670e+01, 3.5000e+01,
5.3000e+00, 1.0000e+01, 3.9500e+01, 1.4120e+01, 9.1000e+01,
6.0000e+00, 1.6246e+02, 1.0000e+01, 9.9300e+00, 1.1000e+01,
2.2000e+01, 6.7500e+00, 1.1000e+01, 6.0000e+00, 1.2000e+00,
1.1000e+01, 1.3000e+01, 1.2000e+01, 3.2310e+01, 6.0000e+00,
1.6000e+01, 3.2800e+01, 1.3000e+01, 1.2400e+01, 1.0000e+01,
1.1087e+02, 4.5600e+01, 1.0040e+01, 1.0000e+01, 1.0080e+02,
1.0210e+02, 3.6400e+01, 1.8700e+00, 2.5600e+01, 6.9000e+00,
2.4040e+01])
type(EQ_data['depth'].values)
numpy.ndarray
Indexing and Slicing¶
Arrays and dataframes have two axes of indices, rows and columns. Remember that python indexing starts at zero, and the end bounds are generally exclusive.
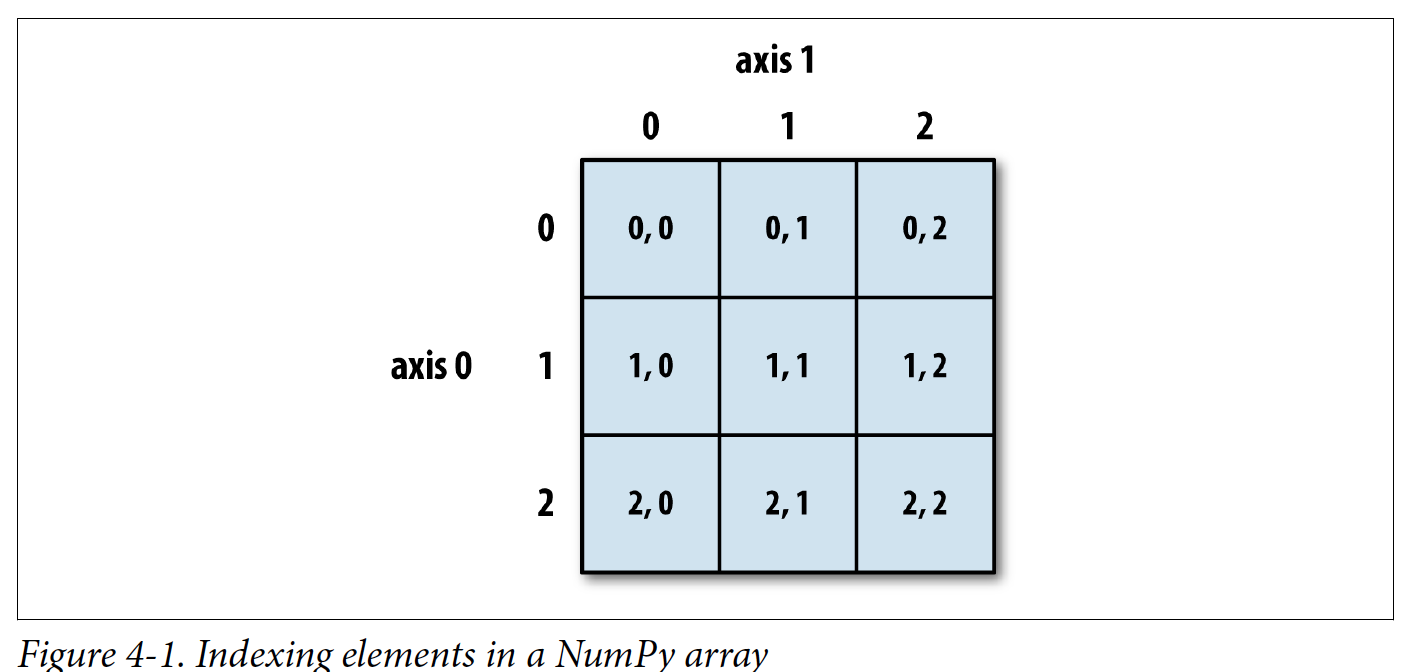
Source: Python for Data Analysis (2nd Edition) McKinney, W.
Using square brackes we can select subsections of tables to work with:
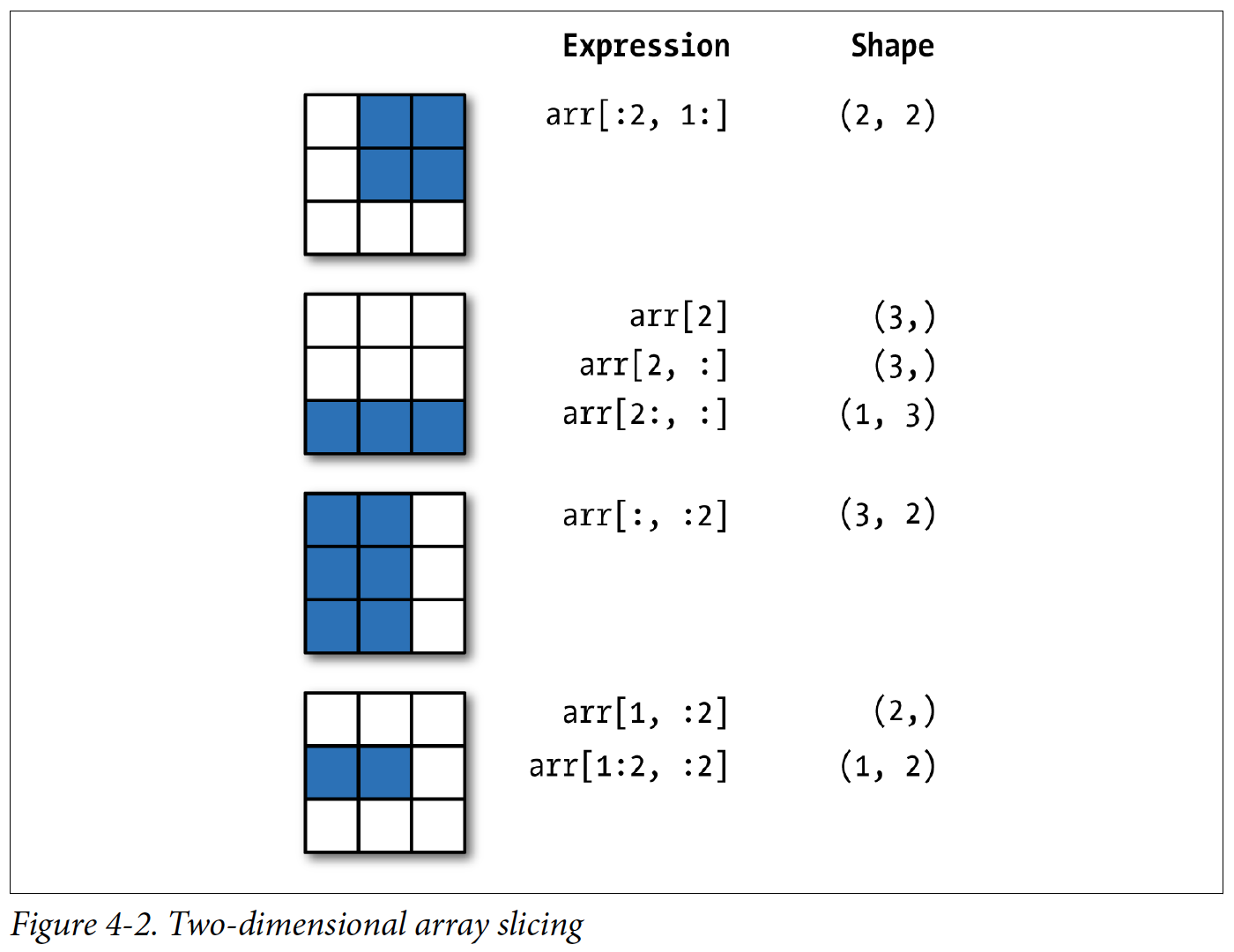
Source: Python for Data Analysis (2nd Edition) McKinney, W.
# generate a random array
arr_data = np.random.randn(10,5)
arr_data
array([[ 4.37604485e-01, 3.26020556e-01, -2.36903924e-03,
4.70153904e-01, 9.61869263e-01],
[-1.12741270e+00, -4.63232607e-01, -1.34920519e+00,
-1.42607446e+00, -1.45081887e+00],
[ 7.84472565e-01, 1.03299394e-01, 5.22566224e-01,
1.08501171e+00, 1.00985635e+00],
[ 3.95527376e-01, 1.83653584e+00, -2.10280867e-01,
1.35102313e+00, 1.98818051e-01],
[-5.92416692e-01, -1.00918554e+00, 4.15165548e-01,
-1.41612380e+00, 2.86959690e-01],
[ 2.48924308e-01, -5.06825885e-01, -9.51352788e-01,
1.13902885e+00, -6.13957882e-02],
[ 1.13111383e+00, -2.26036173e-01, 1.56250412e+00,
-4.93195951e-01, -4.42609029e-01],
[ 2.65890025e-02, 4.01799801e-01, -5.28542140e-01,
5.10127706e-01, -3.85654941e-01],
[-1.63634557e+00, 1.38423520e+00, 3.22007313e-01,
-6.66468990e-01, 2.62433300e+00],
[ 3.11680127e+00, -5.62329638e-01, -4.57055042e-01,
-1.01879027e+00, 8.71575933e-01]])
slice out the first 3 rows of arr_data
a = arr_data[:3]
a
array([[ 0.43760449, 0.32602056, -0.00236904, 0.4701539 , 0.96186926],
[-1.1274127 , -0.46323261, -1.34920519, -1.42607446, -1.45081887],
[ 0.78447257, 0.10329939, 0.52256622, 1.08501171, 1.00985635]])
slice out the last 2 columns of arr_data
b = arr_data[:,-2:]
b
array([[ 0.4701539 , 0.96186926],
[-1.42607446, -1.45081887],
[ 1.08501171, 1.00985635],
[ 1.35102313, 0.19881805],
[-1.4161238 , 0.28695969],
[ 1.13902885, -0.06139579],
[-0.49319595, -0.44260903],
[ 0.51012771, -0.38565494],
[-0.66646899, 2.624333 ],
[-1.01879027, 0.87157593]])
#Or this works too
b = arr_data[:,3:]
b
array([[ 0.4701539 , 0.96186926],
[-1.42607446, -1.45081887],
[ 1.08501171, 1.00985635],
[ 1.35102313, 0.19881805],
[-1.4161238 , 0.28695969],
[ 1.13902885, -0.06139579],
[-0.49319595, -0.44260903],
[ 0.51012771, -0.38565494],
[-0.66646899, 2.624333 ],
[-1.01879027, 0.87157593]])
Slicing a DataFrame is a bit different because you can reference the index labels and use .iloc.
slice out the first 10 rows of EQ_data
EQ_data.iloc[:10]
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | ... | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-09-07T06:12:39.688Z | -17.1102 | 168.5034 | 10.00 | 6.2 | mww | NaN | 41.0 | 2.072 | 1.03 | ... | 2020-11-29T09:47:05.444Z | 72 km NNE of Port-Vila, Vanuatu | earthquake | 6.9 | 1.8 | 0.058 | 29.0 | reviewed | us | us |
| 1 | 2020-09-11T07:35:57.187Z | -21.3968 | -69.9096 | 51.00 | 6.2 | mww | NaN | 72.0 | 0.077 | 0.88 | ... | 2020-11-21T20:10:36.040Z | 82 km NNE of Tocopilla, Chile | earthquake | 6.3 | 1.9 | 0.071 | 19.0 | reviewed | us | us |
| 2 | 2020-09-12T02:44:11.224Z | 38.7482 | 142.2446 | 34.00 | 6.1 | mww | NaN | 47.0 | 2.232 | 0.97 | ... | 2020-11-21T20:10:37.040Z | 58 km SE of Ōfunato, Japan | earthquake | 5.7 | 1.7 | 0.057 | 30.0 | reviewed | us | us |
| 3 | 2020-09-08T00:45:20.853Z | -4.8713 | 129.7548 | 172.00 | 5.9 | mww | NaN | 13.0 | 3.154 | 0.78 | ... | 2020-11-17T19:44:53.040Z | 193 km SSE of Amahai, Indonesia | earthquake | 5.3 | 1.8 | 0.098 | 10.0 | reviewed | us | us |
| 4 | 2020-09-12T08:34:27.321Z | -17.2562 | 167.6792 | 10.00 | 5.9 | mww | NaN | 64.0 | 1.856 | 0.69 | ... | 2020-11-21T20:10:38.040Z | 85 km NW of Port-Vila, Vanuatu | earthquake | 6.8 | 1.9 | 0.043 | 51.0 | reviewed | us | us |
| 5 | 2020-09-07T06:29:14.938Z | -17.1622 | 168.5076 | 10.00 | 5.7 | mww | NaN | 41.0 | 2.116 | 0.83 | ... | 2020-11-17T19:44:50.040Z | 66 km NNE of Port-Vila, Vanuatu | earthquake | 7.0 | 1.8 | 0.050 | 38.0 | reviewed | us | us |
| 6 | 2020-09-09T07:18:40.291Z | 4.1773 | 126.6447 | 17.00 | 5.7 | mww | NaN | 32.0 | 3.062 | 1.17 | ... | 2020-11-21T20:10:33.040Z | 188 km SE of Sarangani, Philippines | earthquake | 6.8 | 1.7 | 0.089 | 12.0 | reviewed | us | us |
| 7 | 2020-09-07T17:40:44.173Z | -24.5115 | -111.9893 | 10.00 | 5.6 | mww | NaN | 34.0 | 3.501 | 1.10 | ... | 2020-11-17T19:44:52.040Z | Easter Island region | earthquake | 10.1 | 1.8 | 0.066 | 22.0 | reviewed | us | us |
| 8 | 2020-09-12T02:37:29.903Z | -17.8804 | -178.0054 | 559.66 | 5.6 | mww | NaN | 36.0 | 3.554 | 1.06 | ... | 2020-11-21T20:10:37.040Z | 284 km E of Levuka, Fiji | earthquake | 9.1 | 4.9 | 0.093 | 11.0 | reviewed | us | us |
| 9 | 2020-09-08T08:28:53.492Z | -15.1737 | -172.9796 | 25.00 | 5.4 | mww | NaN | 54.0 | 1.710 | 0.93 | ... | 2020-11-17T19:44:55.040Z | 123 km NE of Hihifo, Tonga | earthquake | 7.2 | 1.8 | 0.093 | 11.0 | reviewed | us | us |
10 rows × 22 columns
slice out the a chunk of depths starting at index 5 and up to (but excluding) index 10
EQ_data.iloc[5:10]['depth']
5 10.00
6 17.00
7 10.00
8 559.66
9 25.00
Name: depth, dtype: float64
Notice that this is still a Series with corresponding index values. If you just want the values from that chunk and not the index labels use .values.
EQ_data.iloc[5:10]['depth'].values
array([ 10. , 17. , 10. , 559.66, 25. ])
Boolean Indexing¶
We can use Boolean (i.e. logical) indexing to select values from our DataFrame where the argument we want is True. You’ll use the logical symbols (<,>,==,&,|,~).
Use Boolean Indexing to filter out data so that we are only looking at rows with magnitudes larger than or equal to 6.0
EQ_data[EQ_data['mag']>=6.0]
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | ... | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-09-07T06:12:39.688Z | -17.1102 | 168.5034 | 10.0 | 6.2 | mww | NaN | 41.0 | 2.072 | 1.03 | ... | 2020-11-29T09:47:05.444Z | 72 km NNE of Port-Vila, Vanuatu | earthquake | 6.9 | 1.8 | 0.058 | 29.0 | reviewed | us | us |
| 1 | 2020-09-11T07:35:57.187Z | -21.3968 | -69.9096 | 51.0 | 6.2 | mww | NaN | 72.0 | 0.077 | 0.88 | ... | 2020-11-21T20:10:36.040Z | 82 km NNE of Tocopilla, Chile | earthquake | 6.3 | 1.9 | 0.071 | 19.0 | reviewed | us | us |
| 2 | 2020-09-12T02:44:11.224Z | 38.7482 | 142.2446 | 34.0 | 6.1 | mww | NaN | 47.0 | 2.232 | 0.97 | ... | 2020-11-21T20:10:37.040Z | 58 km SE of Ōfunato, Japan | earthquake | 5.7 | 1.7 | 0.057 | 30.0 | reviewed | us | us |
3 rows × 22 columns
Sorting¶
DataFrames can be sorted by the values in a given column (.sort_values).
EQ_data.sort_values(by=['depth']).head()
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | ... | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 298 | 2020-09-11T19:15:33.180Z | 43.528800 | -105.332200 | 0.00 | 3.20 | ml | NaN | 68.0 | 1.10900 | 0.75 | ... | 2020-11-21T20:10:49.040Z | 27 km SSE of Wright, Wyoming | mining explosion | 2.50 | 1.80 | 0.053 | 46.0 | reviewed | us | us |
| 347 | 2020-09-12T16:00:45.986Z | 43.994900 | -105.389800 | 0.00 | 2.90 | ml | NaN | 100.0 | 0.98400 | 0.34 | ... | 2020-11-21T20:10:49.040Z | 26 km SSE of Antelope Valley-Crestview, Wyoming | mining explosion | 6.70 | 1.80 | 0.097 | 14.0 | reviewed | us | us |
| 365 | 2020-09-10T12:09:31.800Z | 44.322333 | -110.520833 | 0.54 | 2.80 | md | 10.0 | 118.0 | 0.05854 | 0.27 | ... | 2020-11-21T20:10:35.040Z | 59 km SE of West Yellowstone, Montana | earthquake | 0.82 | 0.40 | 0.200 | 4.0 | reviewed | uu | uu |
| 402 | 2020-09-10T18:33:51.740Z | 44.333333 | -110.505500 | 1.19 | 2.62 | ml | 17.0 | 125.0 | 0.07115 | 0.18 | ... | 2020-11-21T20:10:35.040Z | 60 km SE of West Yellowstone, Montana | earthquake | 0.57 | 0.50 | 0.264 | 8.0 | reviewed | uu | uu |
| 429 | 2020-09-10T11:40:22.540Z | 44.320333 | -110.497000 | 1.20 | 2.56 | ml | 19.0 | 134.0 | 0.06052 | 0.21 | ... | 2020-11-21T20:10:34.040Z | 61 km SE of West Yellowstone, Montana | earthquake | 0.83 | 0.73 | 0.321 | 8.0 | reviewed | uu | uu |
5 rows × 22 columns
You can reverse the order of sorting with ascending=False.
EQ_data.sort_values(by=['depth'],ascending=False).head()
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | ... | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 168 | 2020-09-07T22:22:20.306Z | -20.8541 | -178.6937 | 605.20 | 4.3 | mb | NaN | 115.0 | 4.359 | 0.82 | ... | 2020-11-17T19:44:53.040Z | Fiji region | earthquake | 14.9 | 8.6 | 0.116 | 21.0 | reviewed | us | us |
| 241 | 2020-09-13T03:50:49.167Z | -21.8264 | -179.4210 | 594.51 | 4.1 | mb | NaN | 112.0 | 4.705 | 0.73 | ... | 2020-11-21T20:10:46.040Z | Fiji region | earthquake | 12.9 | 8.5 | 0.115 | 21.0 | reviewed | us | us |
| 8 | 2020-09-12T02:37:29.903Z | -17.8804 | -178.0054 | 559.66 | 5.6 | mww | NaN | 36.0 | 3.554 | 1.06 | ... | 2020-11-21T20:10:37.040Z | 284 km E of Levuka, Fiji | earthquake | 9.1 | 4.9 | 0.093 | 11.0 | reviewed | us | us |
| 191 | 2020-09-13T03:28:35.972Z | -24.1523 | -179.9576 | 550.77 | 4.3 | mb | NaN | 143.0 | 17.743 | 0.28 | ... | 2020-11-21T20:10:46.040Z | south of the Fiji Islands | earthquake | 19.1 | 13.7 | 0.147 | 14.0 | reviewed | us | us |
| 242 | 2020-09-13T04:05:14.608Z | 6.0551 | 123.8095 | 539.77 | 4.1 | mb | NaN | 76.0 | 2.026 | 0.63 | ... | 2020-11-21T20:10:46.040Z | 45 km WSW of Palimbang, Philippines | earthquake | 15.9 | 14.2 | 0.198 | 7.0 | reviewed | us | us |
5 rows × 22 columns
Data cleaning and inspection¶
.drop() can be used to drop whole columns from a DataFrame.
EQ_data_concise = EQ_data.drop(['magType','nst','gap','dmin','rms','net','id','updated','place','type','horizontalError','depthError','magError','magNst','status','locationSource','magSource',], axis='columns')
EQ_data_concise.head()
| time | latitude | longitude | depth | mag | |
|---|---|---|---|---|---|
| 0 | 2020-09-07T06:12:39.688Z | -17.1102 | 168.5034 | 10.0 | 6.2 |
| 1 | 2020-09-11T07:35:57.187Z | -21.3968 | -69.9096 | 51.0 | 6.2 |
| 2 | 2020-09-12T02:44:11.224Z | 38.7482 | 142.2446 | 34.0 | 6.1 |
| 3 | 2020-09-08T00:45:20.853Z | -4.8713 | 129.7548 | 172.0 | 5.9 |
| 4 | 2020-09-12T08:34:27.321Z | -17.2562 | 167.6792 | 10.0 | 5.9 |
.unique() returns the unique values from the specified object.
unique_mags = EQ_data_concise['mag'].unique()
unique_mags.sort()
unique_mags
array([2.5 , 2.51, 2.53, 2.54, 2.55, 2.56, 2.57, 2.58, 2.6 , 2.61, 2.62,
2.63, 2.64, 2.65, 2.66, 2.68, 2.69, 2.7 , 2.74, 2.75, 2.76, 2.77,
2.78, 2.79, 2.8 , 2.81, 2.82, 2.84, 2.86, 2.9 , 2.91, 2.92, 2.95,
2.96, 2.97, 2.98, 2.99, 3. , 3.01, 3.02, 3.03, 3.06, 3.1 , 3.17,
3.18, 3.2 , 3.21, 3.23, 3.26, 3.3 , 3.32, 3.34, 3.42, 3.43, 3.44,
3.46, 3.5 , 3.53, 3.59, 3.6 , 3.7 , 3.71, 3.72, 3.74, 3.75, 3.8 ,
3.83, 3.9 , 4. , 4.1 , 4.2 , 4.22, 4.3 , 4.33, 4.36, 4.4 , 4.5 ,
4.6 , 4.7 , 4.8 , 4.9 , 5. , 5.1 , 5.2 , 5.4 , 5.6 , 5.7 , 5.9 ,
6.1 , 6.2 ])
.value_counts() returns the count of each unique value from the specified object. This functionality can be used to find duplicate values.
EQ_data_concise['mag'].value_counts()
4.40 38
4.50 35
4.20 32
4.30 31
4.60 31
..
2.69 1
3.53 1
3.72 1
3.21 1
3.44 1
Name: mag, Length: 90, dtype: int64
Finding missing data (NaNs)¶
NaN stands for not a number and is used as a placeholder in data tables where no value exists. np.isnan returns a boolean object with True where NaNs appear in the DataFrame.
np.isnan(EQ_data['nst'])
0 True
1 True
2 True
3 True
4 True
...
446 True
447 False
448 True
449 False
450 True
Name: nst, Length: 451, dtype: bool
~np.isnan(EQ_data['nst'])
0 False
1 False
2 False
3 False
4 False
...
446 False
447 True
448 False
449 True
450 False
Name: nst, Length: 451, dtype: bool
You can use this boolean object to filter-out rows that contain NaNs.
EQ_data[~np.isnan(EQ_data['nst'])]
| time | latitude | longitude | depth | mag | magType | nst | gap | dmin | rms | ... | updated | place | type | horizontalError | depthError | magError | magNst | status | locationSource | magSource | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 162 | 2020-09-12T23:22:04.540Z | 19.304600 | -64.389600 | 40.00 | 4.36 | md | 19.0 | 233.0 | 1.86560 | 0.4800 | ... | 2020-11-21T20:10:38.040Z | 115 km NNE of Cruz Bay, U.S. Virgin Islands | earthquake | 3.57 | 29.63 | 0.060000 | 8.0 | reviewed | pr | pr |
| 163 | 2020-09-13T07:12:58.980Z | 19.396000 | -64.284100 | 35.00 | 4.33 | md | 26.0 | 234.0 | 2.00520 | 0.2900 | ... | 2020-11-21T20:10:39.040Z | 129 km NNE of Cruz Bay, U.S. Virgin Islands | earthquake | 1.81 | 21.72 | 0.130000 | 16.0 | reviewed | pr | pr |
| 195 | 2020-09-11T07:55:45.450Z | 36.440667 | -117.994500 | 3.93 | 4.22 | ml | 45.0 | 66.0 | 0.06908 | 0.1800 | ... | 2020-11-21T20:10:36.040Z | 18km SSE of Lone Pine, CA | earthquake | 0.18 | 0.57 | 0.140000 | 320.0 | reviewed | ci | ci |
| 260 | 2020-09-08T01:19:54.510Z | 19.121300 | -64.398500 | 38.00 | 3.83 | md | 17.0 | 338.0 | 1.74990 | 0.4000 | ... | 2020-11-17T19:44:53.040Z | 96 km NNE of Cruz Bay, U.S. Virgin Islands | earthquake | 3.23 | 24.52 | 0.110000 | 14.0 | reviewed | pr | pr |
| 261 | 2020-09-08T06:35:40.270Z | 19.316600 | -64.570800 | 37.00 | 3.83 | md | 20.0 | 335.0 | 1.73570 | 0.4100 | ... | 2020-11-17T19:44:54.040Z | 111 km NNE of Cruz Bay, U.S. Virgin Islands | earthquake | 3.32 | 26.87 | 0.120000 | 10.0 | reviewed | pr | pr |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 435 | 2020-09-08T11:03:53.600Z | 18.027300 | -66.828000 | 16.00 | 2.51 | md | 12.0 | 117.0 | 0.07310 | 0.1500 | ... | 2020-09-08T11:14:28.314Z | 2 km ESE of Yauco, Puerto Rico | earthquake | 0.58 | 0.73 | 0.150000 | 5.0 | reviewed | pr | pr |
| 436 | 2020-09-13T17:55:42.130Z | 19.182333 | -155.475833 | 32.80 | 2.51 | md | 59.0 | 82.0 | NaN | 0.1200 | ... | 2020-11-21T20:10:40.040Z | 2 km S of Pāhala, Hawaii | earthquake | 0.44 | 0.60 | 0.152709 | 27.0 | reviewed | hv | hv |
| 437 | 2020-09-07T08:24:04.300Z | 17.932000 | -66.947100 | 13.00 | 2.50 | md | 16.0 | 221.0 | 0.08040 | 0.1300 | ... | 2020-09-07T09:46:21.114Z | 6 km SW of Guánica, Puerto Rico | earthquake | 0.79 | 0.30 | 0.120000 | 11.0 | reviewed | pr | pr |
| 447 | 2020-09-11T12:23:38.700Z | 44.315167 | -110.494500 | 1.87 | 2.50 | ml | 15.0 | 144.0 | 0.05648 | 0.1800 | ... | 2020-11-21T20:10:36.040Z | 61 km SE of West Yellowstone, Montana | earthquake | 0.50 | 2.06 | 0.377000 | 8.0 | reviewed | uu | uu |
| 449 | 2020-09-12T05:56:08.720Z | 38.169800 | -117.964800 | 6.90 | 2.50 | ml | 28.0 | 47.8 | 0.03100 | 0.1599 | ... | 2020-11-21T20:10:37.040Z | 27 km SSE of Mina, Nevada | earthquake | NaN | 0.60 | 0.290000 | 15.0 | reviewed | nn | nn |
103 rows × 22 columns
Further Reading (Optional)¶
This user guide has lots of useful examples and documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html